Abstract
BACKGROUND: Viral outbreaks, such as the 2014 ebolavirus, can spread rapidly and have complex evolutionary dynamics, including coinfection and bulk transmission of multiple viral populations. Genomic surveillance can be hindered when the spread of the outbreak exceeds the evolutionary rate, in which case consensus approaches will have limited resolution. Deep sequencing of infected patients can identify genomic variants present in intrahost populations at subclonal frequencies (i.e. <50%). Shared subclonal variants (SSVs) can provide additional phylogenetic resolution and inform about disease transmission patterns.
METHODS: We use metrics from population genetics to analyze data from the 2014 ebolavirus outbreak in Sierra Leone and identify phylogenetic signal arising from SSVs. We use methods derived from information theory to measure a lower bound on transmission bottleneck size.
RESULTS AND CONCLUSIONS: We identify several SSV that shed light on phylogenetic relationships not captured by consensus-based analyses. We find that transmission bottleneck size is larger than one founder population, yet significantly smaller than the intrahost effective population. Our results demonstrate the important role of shared subclonal variants in genomic surveillance.
Funding Statement
This work was supported by the NIH Grant U54 CA121852 and the Defense Threat Reduction Agency Project HDTRA1-14-1-0016. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript. The authors declare that no competing interests exist.Background
The West African ebolavirus outbreak arose in Guinea in late winter of 2014. As of December 10, 2014 there were 17,908 reported cases, with fatality rates as high as 75% in the most widely affected countries.1 Despite the severity of the outbreak, genomic sampling of viral isolates has been limited.2,3,4 Gire et al.3 reported sequencing of ebolavirus samples from 78 patients collected during the initial introduction of the virus into Sierra Leone. Their analysis identified three distinct phylogenetic lineages and reported an evolutionary rate of ~2×103 per site per year, or roughly one nucleotide change every two weeks. This corresponds to a rate almost twice as high as estimates from previous outbreaks.5 These viral evolutionary dynamics in continuous human-to-human transmission are in agreement with measurements from intra-host evolution of filoviruses in primates.6
Tracking the virus as it evolves during the course of the outbreak is an important goal of genomic surveillance, which has been facilitated with high-throughput genomics techniques. These techniques can rapidly sequence intrahost viral particles to high depth and provide estimates of allele frequencies at each position. Consensus-based approaches, which represent each patient with the majority allele measured at each position, have an inherent resolution of a single nucleotide. When the timescale of the outbreak is shorter than the average evolutionary time, as is the case with the 2014 ebolavirus outbreak, there will be insufficient genetic diversity for consensus approaches to provide good resolution into the evolution of the infectious agent. This suggests additional methods to gain what we term subnucleotide resolution into the evolutionary history of the outbreak.
Many samples in the Sierra Leone cohort were sequenced at sufficient depth to call subclonal variants, and initial analysis alluded to the presence of intrahost diversity and shared subclonal variants (SSVs).3 Based on genomic analysis as well as epidemiological data, Schieffelin et al.4 reconstructed possible transmission chains; however, both studies missed evidence of SSVs that were later observed fixed in the cohort. Further, neither study attempted to integrate SSVs into a phylogenetic analysis, and while each suggested the presence of multiclonal transmissions, they did not attempt to assess the effective bottleneck size during possible direct transmissions or within the cohort.
Here, we incorporate subclonal diversity into a phylogenetic analysis using metrics from population genetics, following suggestions in Spielman et al.7 We identify several variants whose shared presence at subclonal frequencies shed light on interesting phylogenetic relationships not captured by consensus-based analyses. Finally, we introduce an information-theoretic method with which we estimate effective viral population size within a patient and during a transmission. When consensus diversity is limited and the outbreak spread exceeds the evolutionary rate, we show that measurement of subclonal diversity can provide valuable information for genomic surveillance.
Results
Subclonal variants. We performed variant calling on the Sierra Leone cohort from Gire et al.3 using the 1976 Zaire isolate as reference. Because we were interested in confidently identifying SSVs, we retained only samples with mean sequencing depth ≥500×, which allowed us to obtain frequency estimates as low as 0.5% in 75 of the original 98 samples, from 64 of the original 78 patients. We identified an average of 568 variants per sample (range 559 to 582). Compared to the 1976 Zaire isolate, 541 variants were fixed in all Sierra Leone samples and 37 were found fixed during the current outbreak in at least one sample. We found 10 variants with frequencies ranging from ≥50% to <100%, and detected 221 subclonal variants at <50%, 45 of which were present in more than one sample. In our analysis, we identified all but two variants that Gire et al.3 reported, in addition to eight SSVs that they missed. Four of these variants were also found fixed in the cohort. Our analysis retained five patients with two, one patient with three, and one patient with four temporal samples
Phylogenetic patterns arising from SSVs. To incorporate the subnucleotide information from SSVs, we used Nei’s standard genetic distance,8which assumes genetic differences are due to accumulation of mutations and genetic drift (Figure 1A). In patients with longitudinal data, we found limited variation in estimates of diversity during the course of the disease (Figure 1B), indicating the absence of hard selection sweeps and/or small population size effects after diagnosis. We also found stronger consensus-based similarity between pairs of samples with SSV compared to those without SSV (rank-sum test p-value: 5.1e-8), consistent with the expectation that samples sharing subclonal variants should be more related than those with no common subclonal variants (Figure 1C).
A) Consensus-based distances have inherent resolution of a single nucleotide; however, intrahost subclonal variants provide subnucleotide resolution. Red dots represent pairwise consensus distances and blue dots represent pairwise Nei’s genetic distances incorporating subclonal variants. (Here, we only show data collected from the chiefdom of Jawie.) B) There was minimal rise in intrahost genomic diversity during the course of the disease. The dip at the third temporal sample in G4769 corresponded to its lower sequencing depth and less sensitivity in identifying variants compared to patient’s other samples. The relative rise in diversity in G3676 corresponded to 1-2% change in frequency of six variants, still within their allele frequency confidence intervals. C) Samples that shared subclonal variants also had similar consensus genomes. In 26 pairs with SSV (Table 2), the mean pairwise consensus distance was significantly smaller than that of pairs with no SSV (<1 nucleotide=”” in=”” ssv=”” pairs=”” versus=””>2 in non-SSV pairs, rank-sum test p-value: 5.1e-08).
Fig. 1: Subclonal variants.
We used neighbor-joining to construct two phylogenetic trees: a consensus tree based on variants with frequencies ≥50%, and an SSV tree (Figure 2). Examining the consensus tree, we identified three clades, in agreement with previous analyses.3,9Four fixed variants (at sites 800, 8,928, 15,963, and 17,142) defined the split between clade 1 and clades 2 and 3. The split between clade 2 and clade 3 was due solely to a non-coding variant at position 10,218. Within each clade there were several degenerate sequences, and the finest resolution obtained was a single nucleotide. In this case, the sampling period spanned roughly one month, not sufficient time for substantial diversity to accumulate. When we considered the SSV tree, however, we observed that while the broad structure remained identical, the addition of subclonal information broke several degeneracies and introduced new branching patterns not observed in the consensus tree. We first noted the overwhelming role played by position 10,218 in generating the tree. We then highlighted notable substructures in the SSV tree and assigned them cluster labels. In particular, we identified seven clusters with phylogenetic relationships that arose due to the effect of SSVs (summarized in Table 1).
Table 1: Summary of seven clusters with phylogenetic relationships that arose due to the effect of SSVs.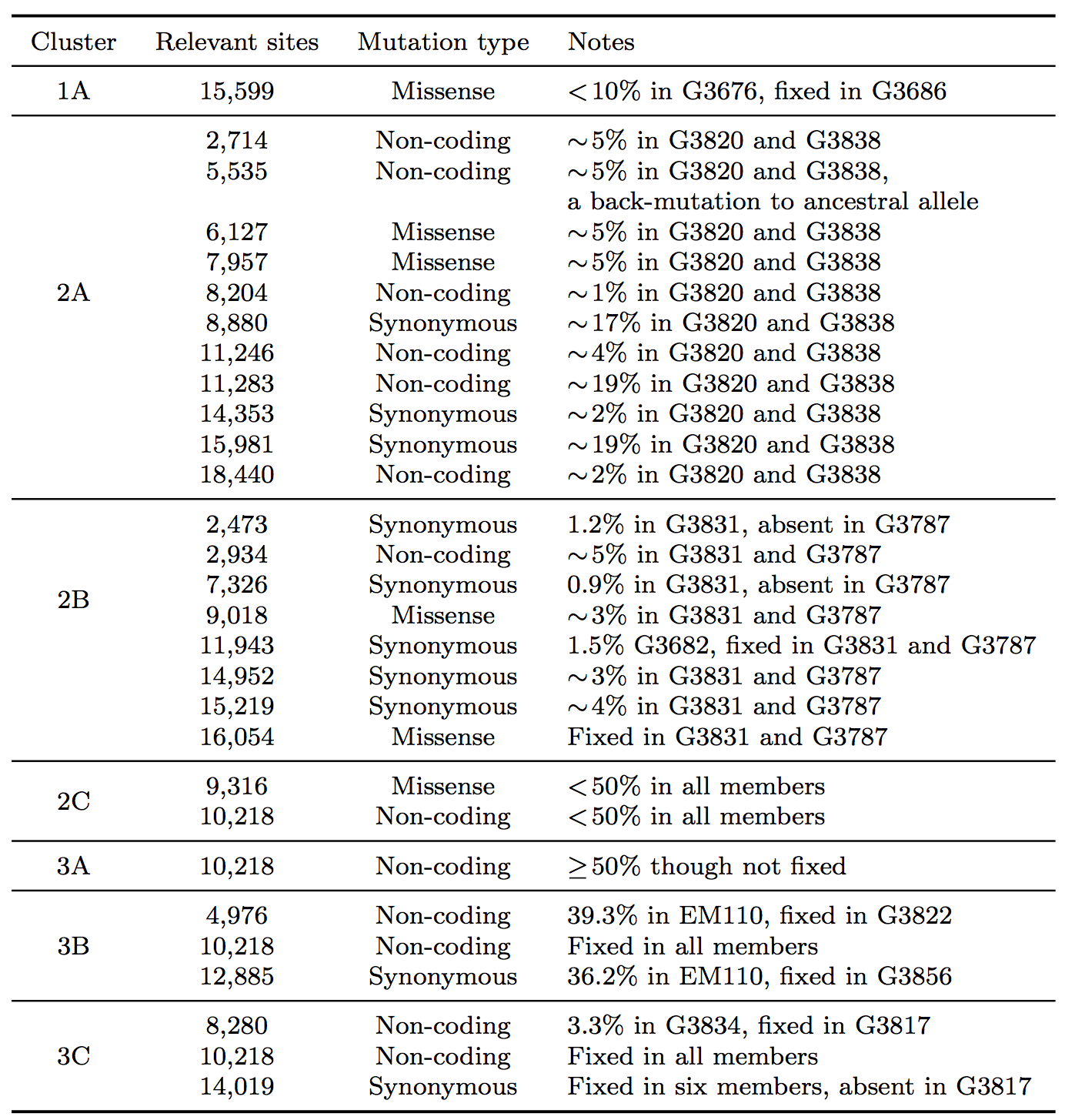
In clade 1, a missense variant at site 15,599 rose from 7.5% in G3676 to become fixed in G3686. This defined cluster 1A. In clade 2, a synonymous variant at site 11,943 present at 1.5% in G3682 later became fixed in two patients, G3787 and G3831, constituting cluster 2A. A set of eleven shared variants between patients G3820 and G3838, including a possible back-mutation to the ancestral allele at position 5,535, defined cluster 2B. A set of samples that contained the variant at position 10,218 at <50%, as well as a unique SSV at position 9,316 (range 1.3% to 17.9%), defined cluster 2C.
In clade 3, cluster 3A was defined by the set of samples for which the variant at position 10,218 was present at >50% though not fixed. Cluster 3B represented an interesting relationship that was not visible in the consensus data. G3822 harbored a synonymous variant fixed at position 4,976 and G3856 harbored a synonymous variant fixed at position 12,885. In the consensus, no evidence existed to bring these two together, however we identified EM110, which harbored the variant alleles at both sites at <50%. This directly implicated EM110 as a putative ancestor of G3822 and G3856, with the two mutations existing unphased in EM110.
A non-coding variant at site 8,280, present at 3.3% in G3834, was found fixed in G3817. Because G3834 shared another fixed variant with other five patients, all seven patients were grouped together, defining cluster 3C. However, no phylogenetic relationship was consistent with this observed pattern, leading us to hypothesize either homoplasy or possible coinfection.
Finally, there were several SSVs that were shared between patients, but neighbor-joining did not bring together. A synonymous variant at site 10,509, present at only 1.3% in EM111, was observed fixed in G3724. These two patients also harbored the variant at site 10,218 at 78% in EM111 and 100% in G3724, suggesting EM111 a plausible transmission ancestor of G3724. A shared subclonal variant at position 7,326 in G3831 (0.9%) and G3827 (6.25%) was the sole subclonal variant shared across clades 2 and 3. Again, homoplasy or coinfection are possible hypotheses to account for this pattern. Nonetheless, we do not suggest these patterns form persistent subclades, simply that they involve interesting patterns not discernible in a consensus analysis. Moderate bootstrap support is attributable to the low number of segregating sites in such a short sampling period. However, the addition of SSVs both enhances support for consensus clades and generates support for new subclades.
The left panel shows a neighbor-joining tree constructed using the consensus sequence for each sample. The right panel shows a neighbor-joining tree constructed from incorporating SSVs and distances computed using Nei’s standard method. Specific differences between the two are highlighted and assigned cluster names within their respective clade.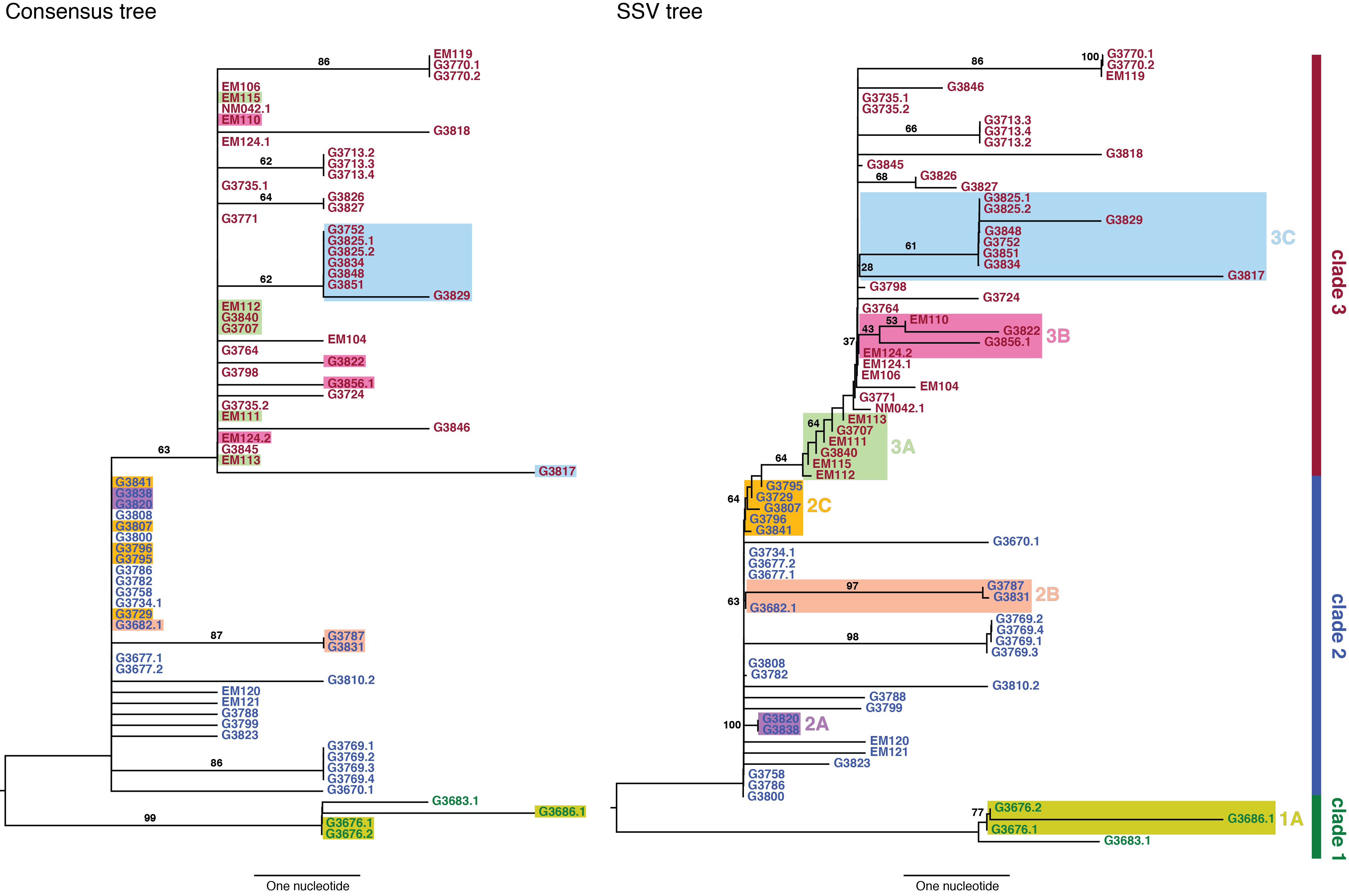
Fig. 2: Consensus and SSV trees.
Transmission bottleneck size and effective viral population. The presence of many shared subclonal variants between patients and the high fraction of reported cases in Sierra Leone from May 25th to June 20th represented by this dataset (~70%)10 strongly suggested direct transmission within this cohort.4 However, comprehensive reconstruction of the exact chain of transmission has not been possible.4,9 Further, shared subclonal variants suggested bulk transmission, implying multiple viral populations can passage between individuals – more than a single founder population. While the idea of bulk transmission has been suggested in HIV,11,12to our knowledge, estimates of transmission bottlenecks from deep sequencing have not been attempted. We therefore estimated the effective population size within a patient and during transmission bottleneck based on an information-theoretic method (Figure 3A).
Here, we assumed minimal rise in diversity during the course of a patient’s disease, in agreement with our observation in seven patients for whom temporal samples were available (Figure 1B). In these patients, we estimated mean intrahost effective viral population size to be at least 105 viral particles (Figure 3B and Table 2). In direct transmission amongst 16 pairs of patients, we found an average lower bound of 102 viral particles effectively representing transmission population size, significantly smaller than the intrahost effective population (rank-sum test p-value: 1.3e-8).
A) Assuming minimal variation in variant frequency during the course of infection, we used binomial sampling to estimate lower bounds on effective transmission bottlenecks. SSVs provide evidence for bulk transmission of viral particles. This approach does not assume direct transmission, and is applicable whenever there is overlap of subclonal variants. B) Our results revealed a transmission bottleneck size significantly smaller than the intrahost effective viral population (rank-sum test p-value: 1.3e-8).
Fig. 3: Effective transmission bottleneck size.
Table 2: Summary of lower bounds on intrahost effective viral population and transmission bottleneck size.
Conclusions
Genomic surveillance promises to shed light on outbreak dynamics; however, when the rate of outbreak expansion exceeds the evolutionary rate, there may be insufficient resolution in consensus analysis to adequately track phylogenetic relationships. Advances in sequencing technologies now allow discovering very rare variants present in 1 out of 1,000 viral particles in each patient.6 The study of viral evolutionary dynamics will benefit from treating patients as populations of viruses rather than a collection of single genomes. Our application of Nei’s standard genetic distance in reconstruction phylogenetic relationships incorporates population genetics methodologies. Tracking shared subclonal variants provides further information when tracking disease transmission and enhances resolution of evolutionary relationships to scales in the order of transmission time. In addition, the information from SSV helps elucidate transmission processes beyond traditional consensus-based approaches, informing on the number of viral particles involved and potential sources of coinfections.
A caveat of our method is that it does not incorporate temporal information. Time in the case of 2014 ebolavirus outbreak can be a confounder, as the reported sampling time will not reflect where in the course of the infection a patient currently resides. This is of particularly important concern when the time scale of data collection is very short, on the same order as the infection period. Future work should focus on incorporating spatial and temporal annotations into the model.
Methods
Identifying shared subclonal variants. Raw sequencing reads from Gire et al.3 were obtained from BioProject PRJNA257197. We mapped the reads to 1976 Zaire ebolavirus isolate (GenBank: NC_002549) using the Bowtie 2 aligner.13 Because we were interested in calling shared subclonal variants, we limited our analysis to samples with mean coverage depth ≥500×. To identify statistically significant variants, we used the SAVI (Statistical Algorithm for Variant Identification) algorithm,14 which constructed empirical priors for the distribution of variant frequencies. From that prior, we obtained a corresponding high-credibility interval (posterior probability ≥1-10-5) for the frequency of each variant. Variants were considered present when observed with a lower bound frequency ≥0.5%. In some samples, due to higher sequencing depth, we were able to obtain frequency estimates below 0.5%; however, we chose this threshold to maintain consistent power for discovering variants at the cohort’s mean sequencing depth of 2,000×.15 We filtered the variants for indel systematic sequencing errors mapping within homopolymeric tracts, and excluded adjacent, phased variants with highly correlated frequencies across all samples. We assessed variants’ strand bias against the dominant allele at their position using Fisher’s exact test. For patients with temporal samples, we excluded variants when the strand bias was significant in all samples (p-value <0.01). We applied a similar criterion to pairs of samples when calculating genetic distances and bottleneck sizes.
Reconstructing phylogenetic trees. To compare viral populations between samples, we used Nei’s standard genetic distance.8 If there existed s number of shared variants between samples 1 and 2,
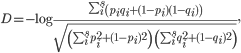
with pi and qi as the frequencies of variant i in samples 1 and 2, respectively. We constructed phylogenetic trees using the neighbor-joining method as implemented in PHYLIP.16 Other genetic distances such as Nei’s DA and Nei’s minimum genetic distance produced similar results.17,18 Bootstrap support was calculated from 1000 replicates using the SumTrees program in DendroPy.19
Estimating effective bottleneck size. We assumed independence between variants and minimal variation in their frequencies during the course of a patient’s disease, consistent with the collected data, and estimated a lower bound on transmission bottleneck size with methods derived from information theory (Figure 3A). We applied a similar approach to estimate effective population size within a patient when temporal data were available.
If there existed ni copies of virus harboring variant i in sample 1, the probability of observing mi viral particles with the same variant in sample 2 could be described with binomial sampling as
with N as the bottleneck size. After changing the variable ni to Npi and mi to Nqi, respectively, for s number of shared variants, the likelihood of the observed state would become
We then followed Stirling’s approximation for factorials,
and derived the log-likelihood to be
with KL(qi | pi) representing the Kullback-Leibler divergence of qi from pi.20 Therefore, the maximum likelihood estimate of N, describing the lower bound on effective bottleneck size, was
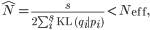
with variance
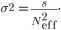
We calculated effective bottleneck size for pairs of patients who shared at least one non-fixed variant, excluding the variant at site 10,218. We calculated Neff in both orientations, from sample 1 to sample 2 and vice versa. We would like to emphasize that this is a lower bound on Neff as sequencing of viral populations in each sample should be considered as additional Markov processes.
Correspondence
Correspondence should be addressed to Hossein Khiabanian ([email protected]) and Raul Rabadan ([email protected]).
Acknowledgements
We thank Marta Luksza, Daniel Rosenbloom, and Ohad Balaga for helpful discussions.References
- Update: Ebola Virus Disease Epidemic - West Africa, December 2014. MMWR Morb Mortal Wkly Rep. 2014 Dec 19;63(50):1199-1201. PubMed PMID:25522088.
- Baize S, Pannetier D, Oestereich L, Rieger T, Koivogui L, Magassouba N, Soropogui B, Sow MS, Keïta S, De Clerck H, Tiffany A, Dominguez G, Loua M, Traoré A, Kolié M, Malano ER, Heleze E, Bocquin A, Mély S, Raoul H, Caro V, Cadar D, Gabriel M, Pahlmann M, Tappe D, Schmidt-Chanasit J, Impouma B, Diallo AK, Formenty P, Van Herp M, Günther S. Emergence of Zaire Ebola virus disease in Guinea. N Engl J Med. 2014 Oct 9;371(15):1418-25. PubMed PMID:24738640.
- Gire SK, Goba A, Andersen KG, Sealfon RS, Park DJ, Kanneh L, Jalloh S, Momoh M, Fullah M, Dudas G, Wohl S, Moses LM, Yozwiak NL, Winnicki S, Matranga CB, Malboeuf CM, Qu J, Gladden AD, Schaffner SF, Yang X, Jiang PP, Nekoui M, Colubri A, Coomber MR, Fonnie M, Moigboi A, Gbakie M, Kamara FK, Tucker V, Konuwa E, Saffa S, Sellu J, Jalloh AA, Kovoma A, Koninga J, Mustapha I, Kargbo K, Foday M, Yillah M, Kanneh F, Robert W, Massally JL, Chapman SB, Bochicchio J, Murphy C, Nusbaum C, Young S, Birren BW, Grant DS, Scheiffelin JS, Lander ES, Happi C, Gevao SM, Gnirke A, Rambaut A, Garry RF, Khan SH, Sabeti PC. Genomic surveillance elucidates Ebola virus origin and transmission during the 2014 outbreak. Science. 2014 Sep 12;345(6202):1369-72. PubMed PMID:25214632.
- Schieffelin JS, Shaffer JG, Goba A, Gbakie M, Gire SK, Colubri A, Sealfon RS, Kanneh L, Moigboi A, Momoh M, Fullah M, Moses LM, Brown BL, Andersen KG, Winnicki S, Schaffner SF, Park DJ, Yozwiak NL, Jiang PP, Kargbo D, Jalloh S, Fonnie M, Sinnah V, French I, Kovoma A, Kamara FK, Tucker V, Konuwa E, Sellu J, Mustapha I, Foday M, Yillah M, Kanneh F, Saffa S, Massally JL, Boisen ML, Branco LM, Vandi MA, Grant DS, Happi C, Gevao SM, Fletcher TE, Fowler RA, Bausch DG, Sabeti PC, Khan SH, Garry RF. Clinical illness and outcomes in patients with Ebola in Sierra Leone. N Engl J Med. 2014 Nov 27;371(22):2092-100. PubMed PMID:25353969.
- Carroll SA, Towner JS, Sealy TK, McMullan LK, Khristova ML, Burt FJ, Swanepoel R, Rollin PE, Nichol ST. Molecular evolution of viruses of the family Filoviridae based on 97 whole-genome sequences. J Virol. 2013 Mar;87(5):2608-16. PubMed PMID:23255795.
- Khiabanian H, Carpenter Z, Kugelman J, Chan J, Trifonov V, Nagle E, Warren T, Iversen P, Bavari S, Palacios G, Rabadan R. Viral diversity and clonal evolution from unphased genomic data. BMC Genomics. 2014 October 17;15(Suppl 6):S17.
- Spielman SJ, Meyer AG, Wilke CO. Increased evolutionary rate in the 2014 West African Ebola outbreak is due to transient polymorphism and not positive selection. bioRxiv. 2014.
Reference Link - Nei M. Genetic Distance between Populations. American Naturalist. 1972; 106(949):283.
- Luksza M, Bedford T, Lassig M. Epidemiological and evolutionary analysis of the 2014 ebola virus outbreak. 2014. arXiv:14111722.
Reference Link - Dixon MG, Schafer IJ. Ebola viral disease outbreak--West Africa, 2014. MMWR Morb Mortal Wkly Rep. 2014 Jun 27;63(25):548-51. PubMed PMID:24964881.
- Keele BF, Giorgi EE, Salazar-Gonzalez JF, Decker JM, Pham KT, Salazar MG, Sun C, Grayson T, Wang S, Li H, Wei X, Jiang C, Kirchherr JL, Gao F, Anderson JA, Ping LH, Swanstrom R, Tomaras GD, Blattner WA, Goepfert PA, Kilby JM, Saag MS, Delwart EL, Busch MP, Cohen MS, Montefiori DC, Haynes BF, Gaschen B, Athreya GS, Lee HY, Wood N, Seoighe C, Perelson AS, Bhattacharya T, Korber BT, Hahn BH, Shaw GM. Identification and characterization of transmitted and early founder virus envelopes in primary HIV-1 infection. Proc Natl Acad Sci U S A. 2008 May 27;105(21):7552-7. PubMed PMID:18490657.
- Carlson JM, Schaefer M, Monaco DC, Batorsky R, Claiborne DT, Prince J, Deymier MJ, Ende ZS, Klatt NR, DeZiel CE, Lin TH, Peng J, Seese AM, Shapiro R, Frater J, Ndung'u T, Tang J, Goepfert P, Gilmour J, Price MA, Kilembe W, Heckerman D, Goulder PJ, Allen TM, Allen S, Hunter E. HIV transmission. Selection bias at the heterosexual HIV-1 transmission bottleneck. Science. 2014 Jul 11;345(6193):1254031. PubMed PMID:25013080.
- Langmead B, Salzberg SL. Fast gapped-read alignment with Bowtie 2. Nat Methods. 2012 Mar 4;9(4):357-9. PubMed PMID:22388286.
- Trifonov V, Pasqualucci L, Tiacci E, Falini B, Rabadan R. SAVI: a statistical algorithm for variant frequency identification. BMC Syst Biol. 2013;7 Suppl 2:S2. PubMed PMID:24564980.
- Rossi D, Khiabanian H, Spina V, Ciardullo C, Bruscaggin A, Famà R, Rasi S, Monti S, Deambrogi C, De Paoli L, Wang J, Gattei V, Guarini A, Foà R, Rabadan R, Gaidano G. Clinical impact of small TP53 mutated subclones in chronic lymphocytic leukemia. Blood. 2014 Apr 3;123(14):2139-47. PubMed PMID:24501221.
- Felsenstein J, Nei M. PHYLIP - Phylogeny Inference Package (Version 3.2). Cladistics. 1989;5:164-166.
- Nei M, Tajima F, Tateno Y. Accuracy of estimated phylogenetic trees from molecular data. II. Gene frequency data. J Mol Evol. 1983;19(2):153-70. PubMed PMID:6571220.
- Nei M, Roychoudhury AK. Sampling variances of heterozygosity and genetic distance. Genetics. 1974 Feb;76(2):379-90. PubMed PMID:4822472.
- Sukumaran J, Holder MT. DendroPy: a Python library for phylogenetic computing. Bioinformatics. 2010 Jun 15;26(12):1569-71. PubMed PMID:20421198.
- Kullback S, Leibler RA. On Information and Sufficiency. Annals of Mathematical Statistics. 1951;22(1):142-143.